
Veri Madenciliği, Dijital teknolojilerin günlük yaşantımızda daha çok kullanılmasıyla birlikte yapılan her işlem dijital ortamda kayıt altına alınmaya başlanmıştır.
Veri madenciliği ilk olarak 90’lı yıllarda ortaya çıkmış ve sonrasında teknolojik gelişmelere paralel olarak her geçen gün gelişmekte ve kullanımı yayılmaktadır. Bu nedenle kullanılan yer ve zamana çeşitli tanımları yapılmıştır.
Gerek bilgisayarlar, akıllı telefonlar ve diğer elektronik aygıtlar üzerinden internet ortamında yapılan işlemler gerekse günlük hayatta rutin olarak yapılan işlemler teknolojik gelişmelerle birlikte veri tabanlarında kayıt altında tutulmaktadır.
Bununla birlikte depolama ünitelerinin veri saklama kapasiteleri hem çok daha gelişmiş hem de daha kolay erişilebilir hale gelmiştir. Zamanla verilerin çok hızla artışı insanlara bu verilerden öz ve faydalı bilgiler çıkarım yapmalarına yöneltmiştir.
Bir anlam ifade etmeyen büyük ölçekli ve gürültülü verilerden anlamlı bilgiler çıkarabilmek için verilerin işlenmesini sağlayan teknikler ve analiz edilen örüntülerin bütününe veri madenciliği denir.
Var olan verilerden çıkarılan veya hesaplanan sonuçlar üreten bir sorgulamanın sonucu olan geleneksel veri tabanlarının aksine veri madenciliği, veriler içerisindeki geçerli, orijinal, işe yarayabilecek ve anlaşılabilir örüntüleri tanıma işlemidir.

Uzun olmayan bir zaman öncesine kadar karar vericilerin ve yöneticilerin karşılaştığı temel problemlerden biri olarak görülen veri kıtlığı, yerini aşırı bolluğa bırakmıştır. Bilgiye erişim endişesinin yerini artık erişilebilinen miktarla başa çıkma endişesi almıştır.
En yaygın tanımlamasıyla Veri madenciliği, büyük ölçekli veriler arasından değeri olan, daha önceden bilinmeyen bir bilgiyi elde etme işidir. Basitçe veri madenciliği, genellikle otomatik olarak toplanan büyük miktarda veriden bilgiyi çıkarma veya madencilik anlamına gelir. Veri madenciliği daha uygun bir şekilde verilerden bilgi madenciliği olarak adlandırılabilir.
Veri madenciliği, veri tabanlarından veya veri ambarlarından elde edilen, çeşitli biçimlerde depolanan, kullanma hazır durumda bulunan büyük ölçekli verilerin içerisindeki gizli kalmış, önceden bilinmeyen ve kullanışlı olduğu düşünülen anlamlı bilgilerin keşfedilmesi sürecidir. Burada dikkat edilmesi gereken önemli hususlardan birisi, elde edilecek bilginin önceden bilinmeyen olmasıdır.
Ulaşılacak bilginin önceden bilinmiyor olmasından kasıt elde edilecek sonucun tahmin edilmemesi anlamını taşımaktadır. Veri madenciliği bilinmeyen bilgiyi ortaya çıkarması veya gelecekte anlamlı hale gelebilecek gizli bilgiyi ortaya çıkarmasıyla diğer yöntemlerden farklılık göstermektedir.
Veri madenciliği aşamalarında tümden gelim değil tüme varım esas alınmaktadır. Büyük ölçekli verilerden ortaya çıkarılan bilgi ile genelleme gidilmesi, kurallar oluşturulması amaçlanır.
Veri madenciliği, araştırma ve çözümleme için birden fazla disiplin arasında köprü görevi yapmaktadır. Bu nedenle uygulama alanı oldukça geniştir. Veri madenciliği yöntemleri genel olarak istatistik, yapay zeka ve yapay zekanın uzantısı olan makine öğrenmesi olmak üzere üç ana kökten beslenmektedir.
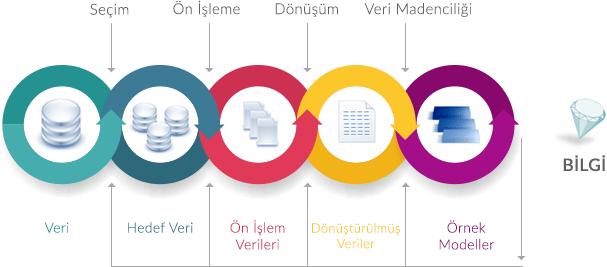
Veri madenciliği verilerdeki örüntüler, değişiklikler, anormallikler ve istatistiksel olarak önemli yapılar ve olayların yarı otomatik keşfidir. Geleneksel veri analizi, bir hipotezin veriye karşı oluşturulduğu ve doğrulandığı anlamında sürdürülebilir. Buna karşılık veri madenciliği, örüntülerin otomatik olarak veriden çıkarılmasıyla elde edilen verilerdir.
Veri madenciliğinde girdi olarak kullanılacak veri setlerinin büyük ölçekli olması analiz aşamasında zaman kaybına, gereksiz ve hatalı sonuçlar elde edilmesine neden olabilmektedir.
Oluşan hataların nedeni, genellikle büyük ölçüdeki veri kümelerinin hatalı ve gürültülü verilerden oluşmasıdır. İşlenecek verinin alındığı veri tabanlarının eksik, net veri içermemesi veri madenciliği sürecinde zorluklara neden olmaktadır.
Veri tabanı; büyük ölçekli verilerden anlamlı bilgiler çıkarmayı amaçlayan veri madenciliğinde veri kümesinin büyüklüğü birtakım zorluklara yol açmaktadır. Büyük veri kümeleri çoğunlukla gürültülü, eksik ve hatalı verileri içermektedir. Veri tabanlarının boyutları günümüzde hızla artmaktadır.
Artan veriler beraberinde birçok kirli veriye neden olmaktadır. Örneklemin büyük olması, örüntülerin gerçekliği açısından bir avantaj olmasına rağmen böyle bir örneklemeden elde edilebilecek olası örüntü sayısı da büyük olacaktır.
Bu yüzden Veri madenciliği sistemlerinin karşı karşıya olduğu en önemli sorunlardan biri veri tabanı boyutunun büyük olmasıdır. Dolayısıyla veri madenciliği yöntemleri ya sezgisel bir yaklaşımla arama uzayını taramalıdır ya da örneklemeyi yatay/dikey olarak indirgemelidir.
Yatayda indirgeme veri alanının örneklenmesi, dikeyde indirgeme ise özelliklerin bulunduğu kolonların azaltılma çalışmasıdır.

Veri Madenciliği, Gürültülü Veri; veri girişi veya verilerin toplanması sırasında oluşan verinin nitelik değerlerindeki eksiklik veya hatalar gürültü olarak adlandırılır. Veri kümesi içinde anlam içermeyen verilerdir. Verilerdeki gürültü ölçülmüş bir özelliğin rassal bir hatası ya da varyansı olan bir değer olarak tanımlanır. Gürültü oluştuysa özellik değerlerinin önceden belirlenmiş kısıtları kullanılarak elle kontrol, ambarlama (binning), kümeleme metotları kullanılarak silinebilir.
Kaynaklardan toplanan veri türlerinde eksik ve kayıplar olabilmektedir. Bu hatalar veri girişi sırasında yapılan insan hataları veya girilen değerin yanlış ölçülmesinden kaynaklanmaktadır.
Eksik veri; veri madenciliğinde kullanılacak olan veri kümesinde bir değer bilinmiyor ya da yanlışlıkla girilmemiş olabilir. Veri madenciliği yöntemlerindeki her verinin bir özellik belirtmesinden dolayı eksik veriler analiz aşamasında sorun yaratmaktadır.
Eksik verilerin doldurulması gerektiğinden veri doldurma işlemi bir ya da çoklu doldurma metotları kullanılarak uygulanır. Tekli veri doldurma metotlarında kayıp değer tek bir değer ile doldurulur. Çoklu veri doldurma metotlarında ise kayıp değeri doldurmada olasılık hesapları ile değerler hesaplanır ve en iyi değer seçilir.
Liste boyunca silme; analizden eksik veriye ait tüm kayıtların silindiği anlamına gelmektedir. Bu teknik genellikle birçok istatistik ve otomatik öğrenme algoritmaları tarafından kullanılır.
İkili silme; eksik değişkenlerin değerleri ile benzer tüm durumlarda bu değişkenin kovaryansının hesaplanmasıdır.
Uygun bir değer atama; kayıp olmayan durumların ortalaması ile kayıp değerlerin atanmasıdır.

Veri madenciliği teknikleri, tanımlayıcı ve tahmin edici olmak üzere iki gruba ayrılır. Tanımlayıcı modeller, karar vermeye yardım edecek verilerin tanımlanmasını sağlar.
Kümeleme (clustering), birliktelik kuralı (association rule), ardışık örüntü (sequential pattern) tanımlayıcı tekniklerden bazılarıdır.
Tahmin edici modeller, keşfe dayalı modellerdir. Sonuçları bilinen verileri kullanarak sonuçları bilinmeyen veri kümelerinin sonuçlarının tahmin edilmesini sağlar.
Sınıflandırma (classification), gerileme (regression), tahmin edici tekniklerden bazılarıdır.
Veri madenciliğinde en çok kullanılan yöntemlerden biri olan sınıflandırma, dağınık bir yapıda bulunan verilere sınıf niteliğinin uygulanması sürecidir. Sınıflama, yeni bir veri elemanını daha önceden belirlenmiş sınıflara atamayı amaçlar.
Verilerin sınıflandırılması için ilk olarak veri tabanının bir kısmı eğitim amacıyla kullanılarak sınıflandırma kuralının oluşturulması sağlanır. Oluşan bu kurallar yardımıyla yeni bir durum ortaya çıktığında nasıl karar verileceği belirlenir.
Sınıflandırma, bir tür öngörü modellemesidir. Diğer bir deyişle, kategorilere ve sınıflara yeni nesneler atama sürecidir. Bir grup etiketli kayıt ele alındığında karar ağacı gibi bir model oluşturulur ve etiketlenmemiş kayıtların etiketleri tahmin edilir. Sınıflandırma sürecinde model oluşturma denetimli öğrenme problemidir .
Sınıflama algoritması öğrenme verilerini kullanarak hangi sınıfların var olduğu ve bu sınıflara girebilmek için kayıtların hangi özelliklere sahip olması gerektiğini otomatik olarak keşfeder. Sınıflama algoritmaları iki şekilde kullanılır .

–Karar Değişkeni ile Sınıflama: Veri kümesi içerisinden seçilen bir karar değişkeninin aldığı değerlere göre sınıflandırma işlemi yapılır. Veri tabanındaki veriler, karar değişkeni olarak belirlenen nitelik değerlerine göre sınıflara ayrılır.
–Örnek ile Sınıflama: Veri tabanındaki veriler pozitif ve negatif olarak iki sınıfa ayrılır. Veriye örnek teşkil eden sınıf belirlendikten sonra veriler sınıflandırılır.
Sınıflamada örneğin yüksek gelir, orta gelir ve düşük gelir gibi üç gruba ya da kategoriye bölümlenebilen gelir kategorisi gibi bir hedef değişken vardır. Veri madenciliği modeli girdi ya da tahminci değişken setindeki gibi hedef değişkenler üzerinde bilgi içeren her bir kaydın büyük setlerini incelemektedir.
Veri Madenciliği, Regresyon analizi süreklilik gösteren değerlerin tahmin edilmesinde kullanılır. Bağımlı bir değişkenin bir veya birden fazla bağımsız değişkenle kurduğu ilişkinin fonksiyon biçiminde yazılmasıdır.
Regresyon analizi değişkenler arasındaki ilişkiyi keşfetmek ve diğer değişkenlere dayalı değişken değerleri tahmin etmek için kullanılabilecek bir veri modeli tasarlamak için kullanılan istatistiksel bir yöntemdir.
Genellikle keşfedilen model doğrusal olmayabilir. Doğrusal regresyon iki veya daha fazla değişken için doğrusal ilişki ve doğrusal veri modelini belirlemek için kullanılan istatistiksel yöntemlere aittir. Basit bir doğrusal regresyon, doğrusal ilişki ve iki genel rastgele değişken arasında doğrusal bir model saptayan en yaygın tekniktir.
Sınıflama ve regresyon arasındaki temel fark tahmin edilen bağımlı değişkenin kategorik veya süreklilik gösteren bir değere sahip olmasıdır. Tahmin edilecek alan eğer sayısal (sürekli) bir değişken ise regresyon problemidir, kategorik bir değişken ise sınıflama problemidir.
Veri Madenciliği, Genel olarak birbirine benzer veya yakın verileri kümelere ayırma yöntemidir. Bir küme benzer olan verilerin toplamından oluşur ve diğer kümelerdeki verilerden farklıdır. Her küme kendi içerisinde anlam ifade etmektedir. Kümeleme işlemi gerçekleştirilirken kümeler içindeki verilerin benzerliği göz önüne alınır.

Kümeleme algoritmaları küme içerisindeki benzer kayıtların maksimize edildiği ve küme dışındaki benzer kayıtların minimize edildiği, ilişkili homojen alt gruplar ya da kümelerin tüm veri setindeki parçalarını araştırır. Kümeleme analizinde sınıf etiketleri başlangıçta bilinmediğinden eğitim verilerinde kolaylıkla bulunmaz. Kümeleme her bir etiketi türetmede kullanılabilir.
Kümeleme tekniği, sınıflamada olduğu gibi verileri gruplara ayırma işlemidir. Kümeleme ile sınıflama arasındaki farklardan bir tanesi, sınıflama işleminde sınıflar önceden belirli iken kümelemede sınıflar önceden belli değildir sahip olunan verinin durumuna göre belirlenir. Bir diğer fark ise kümeleme işleminde eğitim sürecinin bulunmamasıdır. Bunun anlamı verilerin bir model oluşturmak üzere eğitilmemesidir.
Bu doğrultuda kümeleme en temel anlamda iki avantaja sahiptir. Bunlardan ilki, kümelemenin sınıflama tekniğince desteklenen yapıyı gösterebilme yeteneğidir. İkincisi ise, test kümesi sınıflama doğruluk skorları oluşturulan kümelerin kalitesine ilişkin ek bilgi sağlamaktadır.
Veri Madenciliği, Birlikte hareket eden veya belirli bir veri kümesinde büyük sıklıkta birlikte görülen verilerin özelliklerine ait ilişkisel kuralların keşfidir. Başka bir ifadeyle birliktelik kuralı geçmiş verilerin analiz edilerek bu veriler içerisindeki birliktelik davranışlarının tespiti ile geleceğe yönelik çalışmalar yapılmasını destekleyen bir yaklaşımdır.
90’lı yılların başından itibaren veri toplama uygulamalarındaki gelişmeler doğrultusunda firmaların satış noktalarında yeni teknoloji otomatik ürün veya müşteri tanıma sistemleri yaygınlaşmaya başlamıştır.
Bu tip teknolojik gelişmeler bir satış hareketine ait verilerin satış esnasında toplanmasına ve elektronik ortamlara aktarılmasına olanak tanımıştır. Birliktelik kuralının en çok kullanıldığı alan pazar sepeti analizi (Market Basket Analysis) dir.
Bu analiz, yapılan alışverişlerde alınan ürünlerin birbirleriyle olan ilişkisini incelemektedir. Ayrıca market sepeti analizi ile müşterilerin aldığı ürünlerin hareketlerinden gelecekte benzer hareketleri gösteren bir müşterinin nasıl bir tercih yapacağına dair varsayımlar ortaya çıkmaktadır.

Veri Madenciliği, Veri ambarı, sorgulama ve analiz için kullanılmak üzere tasarlanmış ilişkisel bir veri tabanıdır. Veri ambarı, büyük hacimlerdeki verinin analiz edilmesi ile ilgili konular üzerinde odaklanır. Veri tabanını yormamak için oluşturulan yapılardır. Bir veri ambarı farklı kaynaklardan gelen verileri bir araya toplar, hızlı ve doğru biçimde analiz etmek için gerekli işlemleri yerine getirir ve üzerinden raporlar alınmasını sağlamaktadır.
Veri ambarları birbiriyle ilişkisi olmayan veri kaynaklarından aldığı verileri birleştirip bunları karar destek uygulamalarında kullanılmak üzere oluşturulan çok boyutlu gösterim işidir. Geleneksel veri tabanı sistemleri, kullanıcı hareketlerine bağlı günlük işlemleri desteklemek için tasarlanmıştır ve bu sistemler işletimsel ya da hareketsel sistemler olarak adlandırılır.
İşletimsel sistemler hareket ya da işlem yönlendirmeli, veri ambarları ise konu yönlendirmelidir. Veri ambarı, veri tabanı hareketlerinden kaynaklanan iş yüküyle analiz yükünü birbirinden ayırır. Veri tabanının seçimi, veri ambarı sürecinde verilebilecek en önemli kararlardandır.
Kullanılacak veri tabanı artan veri miktarı, kullanıcı sayısı, kullanıcı ihtiyaç ve istekleri doğrultusunda büyüyebilir olmalıdır. Veri ambarı aynı zamanda yapısal veya planlanmamış sorgular, analitik raporlar ve karar vermeyi desteklemek için çeşitli farklı türde kaynaklardan veriyi bütünleştirerek oluşturulan bir mimari olarak da görülebilir.

2014 yılından beri yüzlerce dijital projeye katkı sağlamış olan Codlio ekibi olarak, yaptığımız birçok çalışmada hep insan odaklı hareket ederiz. Kalbimizle hisseder, düşünür ve ellerimizle hayata geçiririz.
İletişime Geç!
YouTube kanalınıza özel URL nasıl oluşturulur? Daha profesyonel ve hatırlanabilir bir görünüm için adım adım rehber. ...

Sosyal medya taraması nasıl yapılır? Marka görünürlüğünüzü artırmak ve rakip analizi için etkili adımlar. Detaylı rehbe...

A/B testi nedir ve nasıl yapılır? İki farklı versiyon arasında karşılaştırmalı testlerle daha etkili sonuçlar elde edin...

Facebook dinamik ürün reklamlarıyla ilgili bilmeniz gerekenler. Ürün kampanyalarınızı optimize etmek için etkili ipuçla...





